
Data Minimization กับ GenAI: เมื่อหลักการป้อนข้อมูลเท่าที่จำเป็นต้องเปลี่ยนไป
หนึ่งในเสาหลักสำคัญของกฎหมายคุ้มครองข้อมูลส่วนบุคคล (PDPA) คือ หลักการประมวลผลข้อมูลเท่าที่จำเป็น (Data Minimization) ซึ่งระบุว่าองค์กรต้องเก็บรวบรวม ใช้ หรือเปิดเผยข้อมูลส่วนบุคคลเฉพาะส่วนที่เกี่ยวข้องและจำเป็นต่อวัตถุประสงค์ของการประมวลผลเท่านั้น
ทว่าเมื่อองค์กรก้าวเข้าสู่ยุคของ Generative AI (GenAI) และโมเดลภาษาขนาดใหญ่ (LLMs) หลักการนี้กำลังเผชิญหน้ากับความย้อนแย้งครั้งใหญ่ (Paradox) เพราะในโลกของ AI “บริบทแวดล้อม” (Context) คือหัวใจสำคัญ ยิ่งโมเดลได้รับข้อมูลและประวัติการสนทนาที่ยาวและกว้างมากเท่าไหร่ AI ก็ยิ่งเข้าใจเจตนาของผู้ใช้ และตอบคำถามได้อย่างแม่นยำโดยไม่เกิดอาการ “หลอน” (Hallucination) มากเท่านั้น
ความขัดแย้งโดยตรงระหว่างข้อจำกัดทางกฎหมายและความต้องการทางเทคโนโลยี ทำให้การทำ Data Minimization รูปแบบเดิมใช้ไม่ได้ผลอีกต่อไป และนี่คือกลยุทธ์สถาปัตยกรรมข้อมูลยุคใหม่ที่องค์กรต้องรู้เพื่อปรับตัวให้เท่าทัน
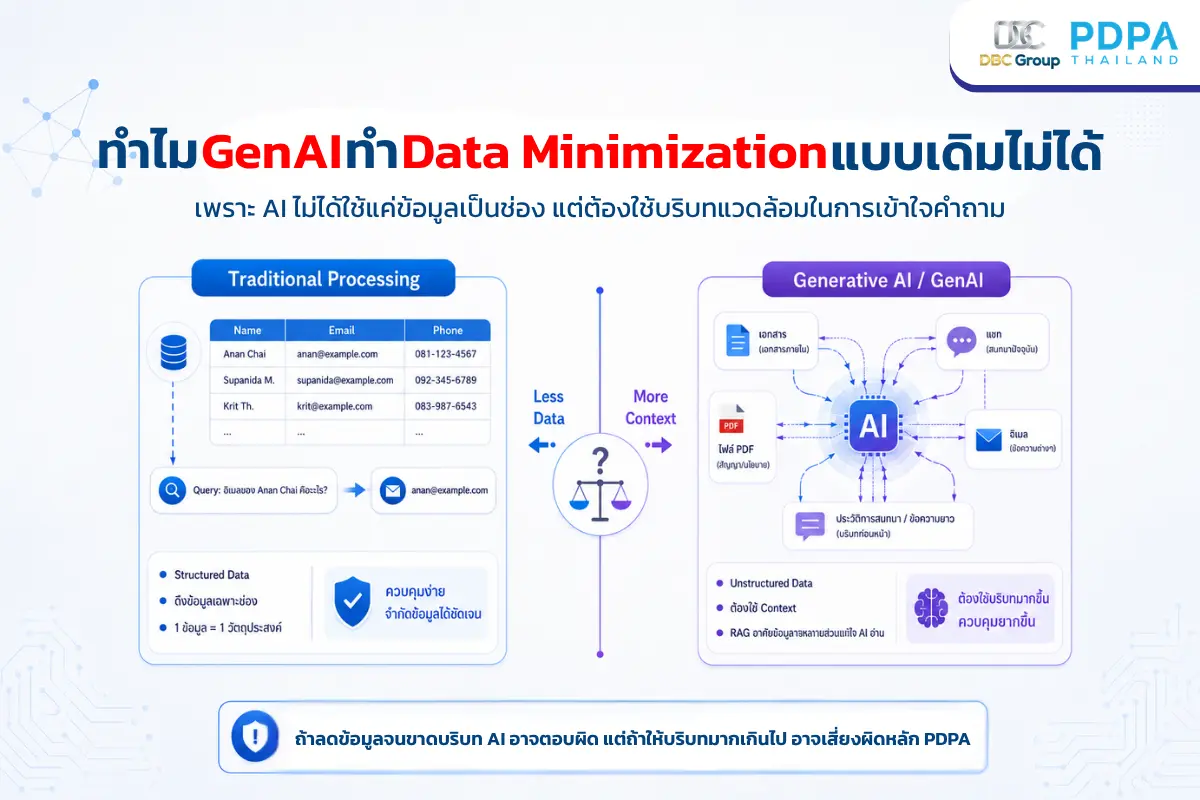
เจาะลึกความขัดแย้ง: ทำไม GenAI ถึงทำ Data Minimization แบบเดิมไม่ได้
การประมวลผลข้อมูลในระบบไอทีดั้งเดิมส่วนใหญ่ใช้ข้อมูลที่มีโครงสร้างชัดเจน (Structured Data) ต่างจากระบบของ GenAI ที่ต้องพึ่งพาข้อมูลไร้โครงสร้าง (Unstructured Data) เพื่อการวิเคราะห์ ดังตารางเปรียบเทียบต่อไปนี้
มิติการเปรียบเทียบ | การประมวลผลข้อมูลแบบดั้งเดิม (Traditional) | ระบบ Generative AI (GenAI) |
โครงสร้างข้อมูล | Structured Data (ล็อกสเปกช่องข้อมูลชัดเจน เช่น ชื่อ, อีเมล, เบอร์โทร) | Unstructured Data (ข้อความแชท, รายงาน, ไฟล์ PDF, ประวัติการคุยยาวๆ) |
ความจำเป็นของข้อมูล | ข้อมูล 1 ช่อง = วัตถุประสงค์ 1 อย่าง (ตรงตามหลัก Minimization ชัดเจน) | ข้อมูลรายรอบ (Context) ทั้งหมด จำเป็นต่อการคำนวณและประมวลผลของ AI |
ขอบเขตการดึงข้อมูล | ดึงเฉพาะเจาะจงผ่านคิวรี (เช่น SELECT email FROM users WHERE id=1) | ระบบ RAG ดึงเอกสารทั้งปึกที่ใกล้เคียงมาให้ AI อ่านเพื่อสรุปคำตอบ |
หากองค์กรบังคับใช้หลัก Data Minimization แบบเข้มงวดเกินไปโดยส่งเฉพาะข้อมูลดิบที่ไร้บริบทเข้าไปในคิวรีหรือ Prompt ผลลัพธ์ที่ได้จาก GenAI จะขาดความแม่นยำและไร้ประสิทธิภาพทันที (Garbage In, Garbage Out)
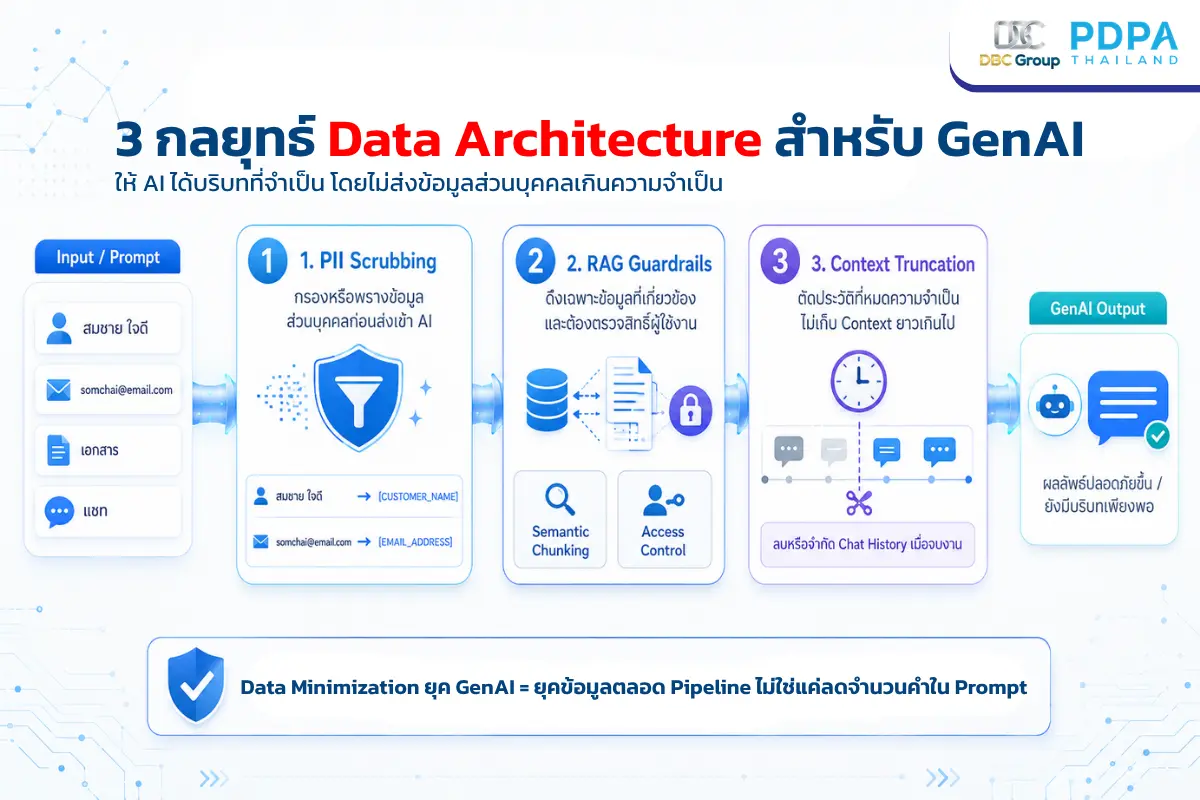
3 กลยุทธ์ออกแบบ Data Architecture สำหรับ GenAI ให้ถูกหลัก PDPA
ในเมื่อเราไม่สามารถจำกัด “ปริมาณบริบท” ที่ AI ต้องการได้ องค์กรจึงต้องเปลี่ยนวิธีคิดจากการจำกัดการเก็บข้อมูล ไปสู่ “การบริหารจัดการท่อส่งข้อมูล” (Data Pipeline Governance) โดยนำเทคนิคและสถาปัตยกรรมข้อมูลรูปแบบใหม่เข้ามาประยุกต์ใช้ดังนี้
1. การทำ Automated PII Scrubbing (การกรองข้อมูลส่วนบุคคลออกจาก Prompt)
แทนที่จะห้ามไม่ให้พนักงานป้อนข้อมูล หรือบังคับให้พิมพ์ข้อความสั้นๆ องค์กรควรติดตั้งระบบตรวจจับและพรางข้อมูลส่วนบุคคล (PII Masking/Scrubbing Tools) ไว้เป็นด่านแรกก่อนที่ข้อมูลจะถูกส่งไปยังโครงข่าย AI หรือ API ภายนอก
ตัวอย่าง: หากพนักงานพิมพ์ป้อนระบบว่า:
“ช่วยสรุปรายงานการประชุมของลูกค้าชื่อ สมชาย ใจดี อีเมล [email protected] หน่อย” > ระบบจะทำการแปลงข้อความอัตโนมัติ (Masking) เป็น:
“ช่วยสรุปรายงานการประชุมของลูกค้าชื่อ [CUSTOMER_NAME] อีเมล [EMAIL_ADDRESS] หน่อย” ก่อนส่งให้ AI
วิธีนี้ช่วยให้ AI ได้บริบทที่กว้างพอในการสรุปเนื้อหาสำคัญตามหน้าที่ โดยที่ไม่มีข้อมูลระบุตัวตนจริงหลุดรอดไปภายนอกองค์กร
2. การวางระบบ Guardrails และ Access Control ในระบบ RAG
ปัจจุบันองค์กรนิยมพัฒนา AI ภายในผ่านสถาปัตยกรรม RAG (Retrieval-Augmented Generation) ซึ่งเป็นการเชื่อมต่อ LLM เข้ากับคลังข้อมูลของบริษัท เพื่อให้ AI ค้นหาและดึงเอกสารภายในมาตอบคำถาม การทำ Data Minimization ในระบบ RAG สามารถทำได้โดย:
- Strict Semantic Chunking: ออกแบบระบบให้แบ่งย่อยเนื้อหาในเอกสาร (Chunking) อย่างมีประสิทธิภาพ และส่งเฉพาะส่วนย่อยที่เกี่ยวข้องกับคำถามที่สุดไปให้ AI ประมวลผล แทนการส่งเอกสารไปทั้งไฟล์
- User-Context Access Control: ต้องผูกสิทธิ์การเข้าถึงข้อมูลของผู้ใช้งาน (User Identity) เข้ากับระบบค้นหาของ RAG เพื่อให้มั่นใจว่า AI จะไม่ไปดึงเอกสารที่ผู้ใช้งานคนนั้นไม่มีสิทธิ์เข้าถึงตั้งแต่แรก (เช่น พนักงานทั่วไปถาม AI แล้วระบบดันไปดึงไฟล์ฐานเงินเดือนจากฝ่ายบุคคลมาสรุปตอบ)
3. Context Window Truncation (การตัดประวัติที่หมดความจำเป็น)
โดยทั่วไป GenAI จะจำประวัติการคุยย้อนหลังเพื่อให้การสนทนาต่อเนื่อง แต่ตามหลักข้อมูลเท่าที่จำเป็น เมื่อการสนทนาสิ้นสุดลงหรือบรรลุวัตถุประสงค์แล้ว องค์กรควรตั้งค่าลบประวัติการสนทนา (Chat History) บนเซิร์ฟเวอร์ หรือจำกัดขนาดของ Context Window ไม่ให้เก็บประวัติยาวนานเกินความจำเป็นในการใช้งานแต่ละครั้ง
มีความเสี่ยงสูงมากที่จะผิดกฎหมาย PDPA หากข้อมูลที่ป้อนลงไปมีรายละเอียดที่สามารถระบุตัวตนลูกค้าได้โดยตรงและไม่ได้ถูกกรองออกก่อน เพราะถือเป็นการส่งมอบข้อมูลส่วนบุคคลให้ระบบภายนอกประมวลผลเกินความจำเป็น ทางแก้คือพนักงานต้องตัดชื่อ ที่อยู่ หรือข้อมูลเฉพาะเจาะจงออก ให้เหลือเพียงประเด็นสำคัญที่ต้องการสื่อสารเท่านั้น
ยังคงต้องทำอย่างเคร่งครัด แม้ความเสี่ยงเรื่องข้อมูลรั่วไหลออกไปภายนอกจะลดลง แต่กฎหมาย PDPA บังคับใช้กับการประมวลผลภายในองค์กรด้วย การปล่อยให้โมเดล AI เข้าถึงข้อมูลทุกประเภทภายในบริษัทโดยไม่มีการจำกัดสิทธิหรือคัดกรองข้อมูลส่วนบุคคล ถือเป็นการประมวลผลข้อมูลเกินความจำเป็นและขัดต่อข้อกฎหมาย
บทสรุป
ในยุคของ Generative AI คำว่า “เท่าที่จำเป็น” ไม่ได้หมายถึงการจำกัดสิทธิการใช้งานจนระบบทำงานไม่ได้ หรือการส่งข้อความสั้นๆ ที่ไร้ใจความสำคัญอีกต่อไป แต่หมายถึง “การให้บริบทที่จำเป็นที่สุดแก่ AI โดยไม่มีข้อมูลระบุตัวตนที่ไม่เกี่ยวข้องปนเปื้อนเข้าไป” องค์กรที่สามารถปรับเปลี่ยนสถาปัตยกรรมข้อมูลให้รองรับการทำ PII Scrubbing และการควบคุมสิทธิ์บนระบบ RAG ได้อย่างมีประสิทธิภาพ จะสามารถปลดล็อกศักยภาพของ GenAI มาสร้างมูลค่าทางธุรกิจได้อย่างเต็มที่ ควบคู่ไปกับการปฏิบัติตามกฎหมาย PDPA อย่างมั่นคงยั่งยืน
เผยแพร่: 26 มิถุนายน 2569
อัปเดตล่าสุด: 26 มิถุนายน 2569
ช่องทางติดต่อ:
Facebook: PDPA Thailand
Line OA: @pdpathailand
Email: [email protected]
Website: www.pdpathailand.com




